研究:xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token¶
論文タイトル(和訳): xRAG:1つのトークンを持つ検索拡張ジェネレーションのための極端文脈圧縮
推論

学習
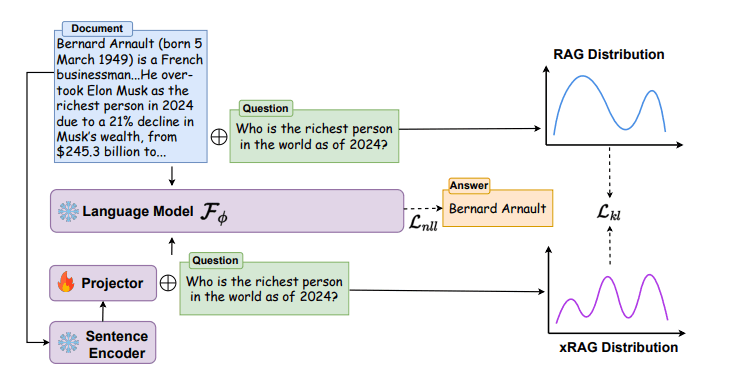
- RAGのための文脈圧縮(Context Compression)手法
- xRAGでは文書ベクトルをモダリティプロジェクタによって1トークンのベクトルに圧縮する
- LLMへのトークン入力が「文書テキスト+問い合わせテキスト」(b)から「文書ベクトル(1トークン)+問い合わせテキスト」(a)になるためトークン消費量が大幅に削減される
- マルチモーダルAIにおけるバイナリベクトル投影に概念が似ている
- チューニング済みLLMインストラクションに対してモダリティプロジェクタの学習を行うイメージ(LLM側はファインチューニングしない)
- 設計/学習
- 2層のMLPで設計されたモダリティプロジェクタをフルスクラッチで学習
- 通常のRAGとxRAGの回答に差がなくなるようにProjectorを学習
- 性能評価
- 論文中でのバックボーンLLMはMistral-7b、Mixtral-8x7b
- 6つの知識集約タスクにおいて一貫して10%以上の性能向上
- 総フロップスを3.53倍削減
- 複数の知識を活用して回答する必要があるようなマルチホップなタスク(HotpotQA)では、従来のRAGには劣る
- 利用
- xRAGのコードやバックボーンLLMについて学習済みのPretrained Projectorはgithubに公開されている
- https://github.com/Hannibal046/xRAG
- 備考
- 将来的に文書データコネクタとしてマルチモーダルLLM側で対応してもらえないのだろうか
特徴¶
- 従来手法との主な違い
- RAG:従来手法(b)
- 検索結果のテキストをそのまま文字列トークン(ベクトル)として渡す
- xRAG:提案手法(a)
- Datastoreの検索結果ベクトルを事前学習したprojectorを用いて圧縮してから渡す
- RAG:従来手法(b)
- 手法のキモ
- 「ドキュメントのベクトルをLLM向けに別のベクトルに変換する」ためのProjector(変換器)
- 学習方法
- 次の2つの回答に差がなくなるようにProjectorを学習させる
- 普通のRAGの通り「関連テキスト+質問」をLLMに渡した場合のLLMの回答
- 「関連テキストをProjectorで変換したベクトル+質問」をLLMに渡した場合のLLMの解凍
- 次の2つの回答に差がなくなるようにProjectorを学習させる
- 制限
- ?日本語対応
- ?LLMモデルへのロバスト性
疑問等¶
- 複数のチャンクに対するベクトルはどのように1トークン化するのか
- 質問文含めて1トークン化できないのか
- どうせ事前計算するならトークン列すべてを使って1トークン圧縮するようなことはしないのか?
参考/引用¶
- RAGで文書を1トークンに圧縮する「xRAG」について
- 概要解説記事
- xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token
- もとの論文
- xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token
- chatgptに入れたやつ
- xRAG github
- pretrainモデルやxRAGのソースコードが公開されている
- マルチモーダルLLMの構築方法
- 参考:コネクタの学習が似ている