研究:Hierarchical Navigable Small Worlds (HNSW)¶
論文タイトル(和訳): 階層型ナビゲータブル小世界グラフを用いた効率的かつ堅牢な近似最近傍探索
概要¶
- グラフ理論ベースの近似K最近傍探索
- クエリのレイテンシーとRecallのトレードオフが最も優れている
- Graph based Nearest Neighbor Search:Promises and Failures
- メモリ効率は悪いので量子化ベクトルを使うなどの工夫をしたほうが良い
NSWの探索概念図
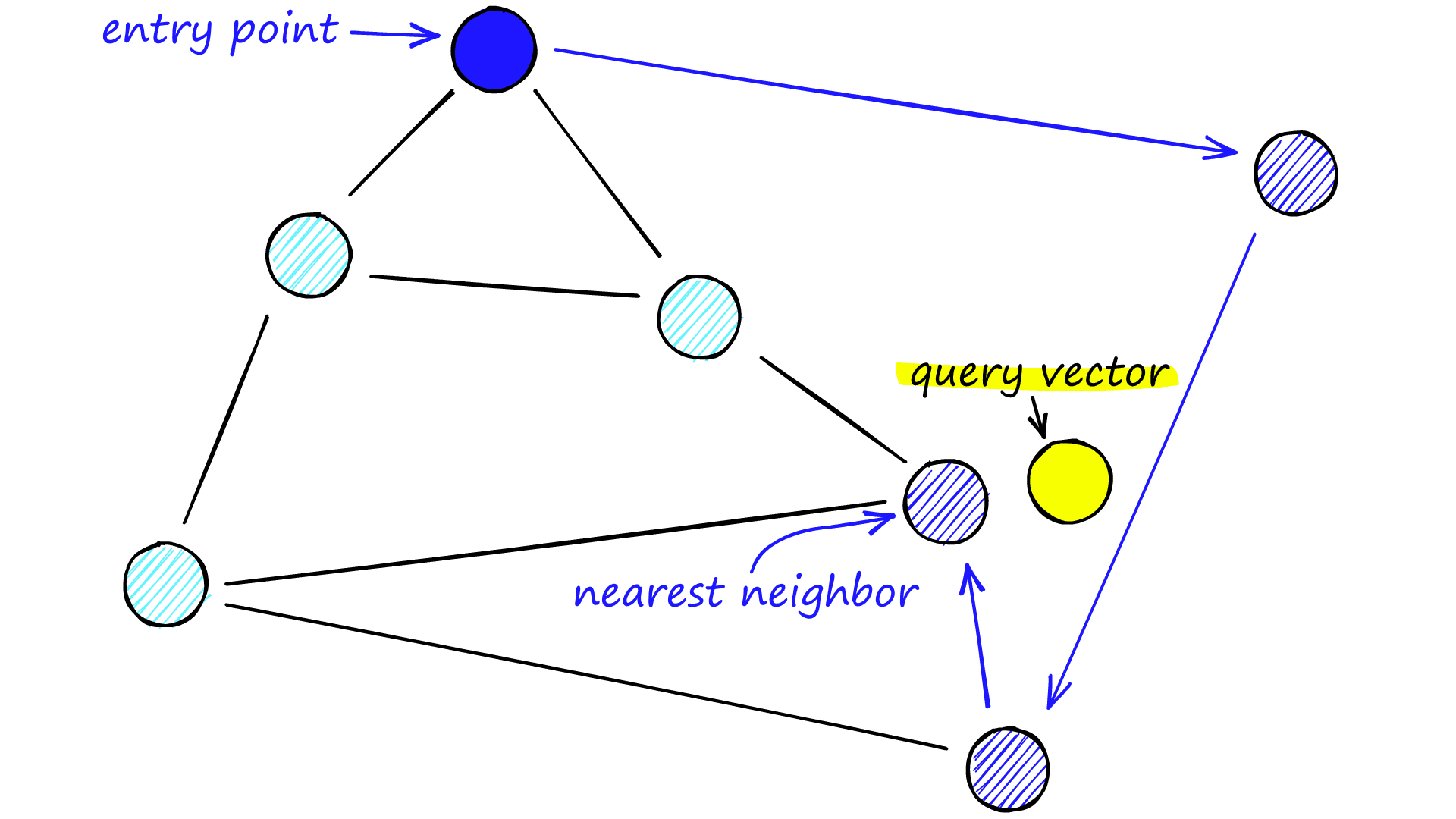
HNSWの探索概念図
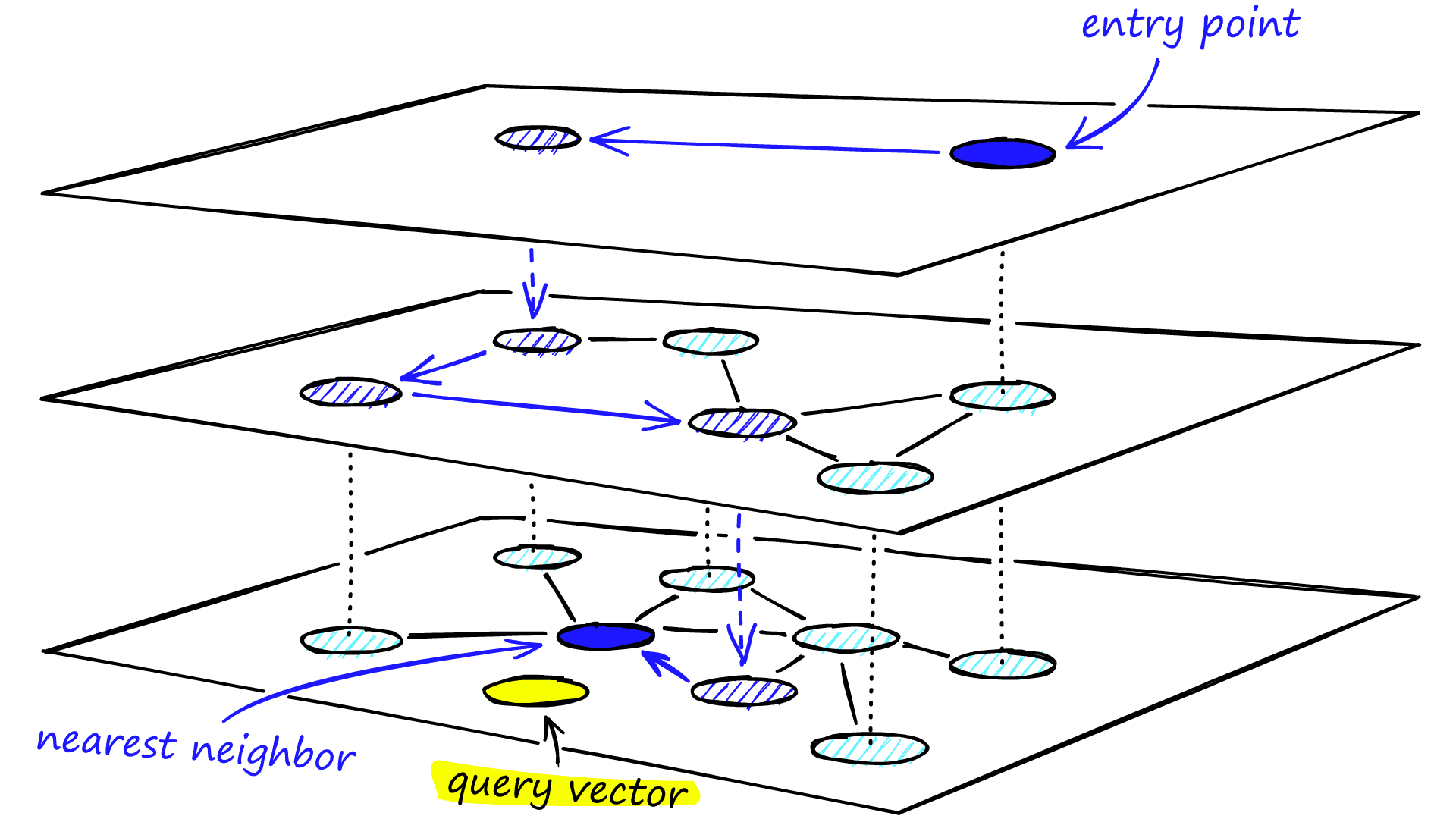
ネットワーク構築時の概念図
特徴¶
- 探索
- nswを用いてグラフ探索することで、目標のベクトルの近傍ノードを見つける。このnswを階層的に扱うのがhnsw。
- 急行に乗って大きく移動してから各駅停車で小さく移動しなおすイメージ
- 急行で飛ばした駅について考慮しなくていい
- 各停に乗ったあとに急行には乗らない
- 特性上、得られる解は近似解
- 構築
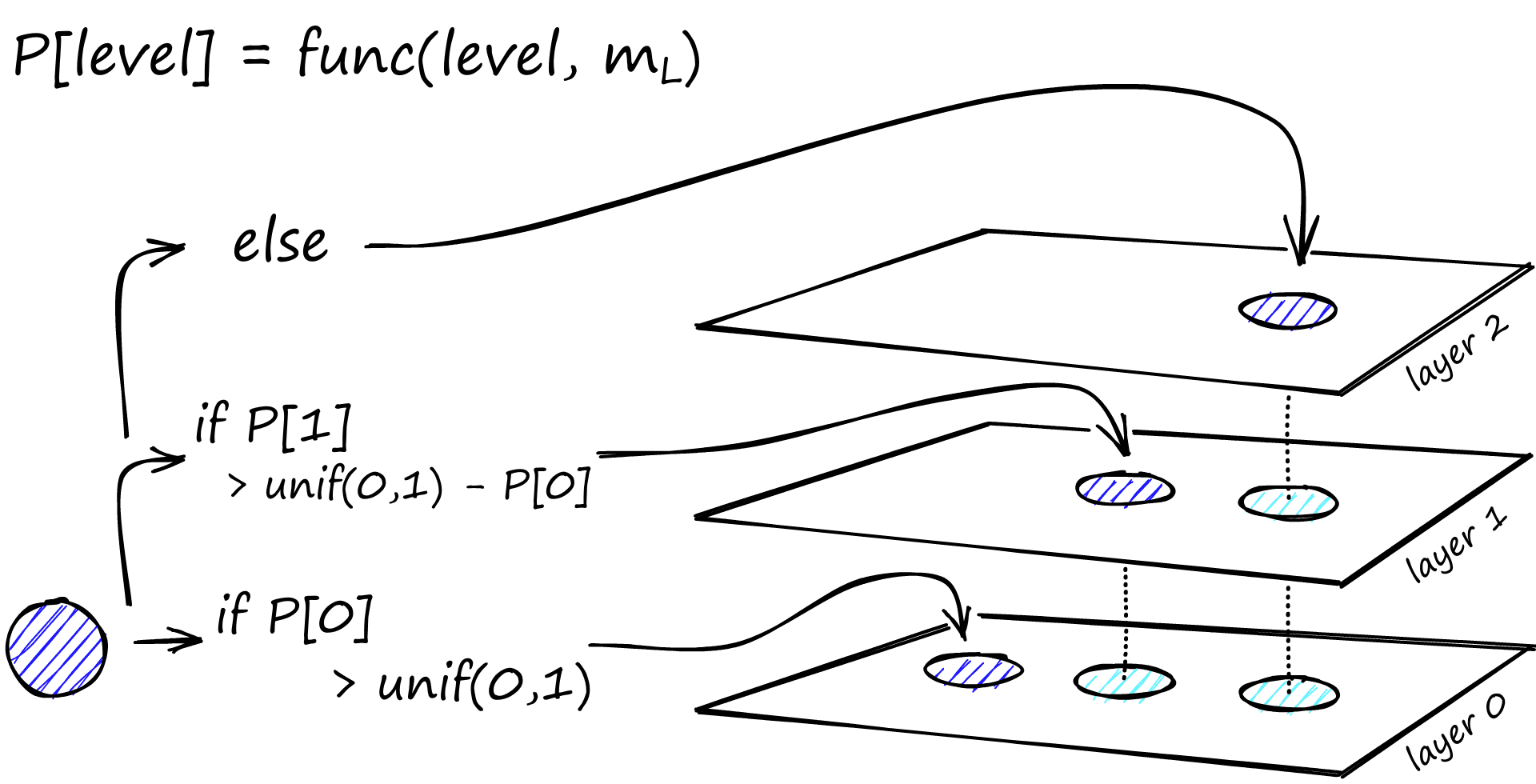
- 全ノードのネットワークから確率()でノード選定して濃度の薄いネットワークを階層的に構築する
- ノード追加時は確率でどのレイヤまでノードを追加するかを決める
- データをあとから追加しても問題がない
- レイヤ数は経験則からとするのが良い
- 全ノードのネットワークから確率()でノード選定して濃度の薄いネットワークを階層的に構築する
- パラメータ
- 以下のようなパラメータによりレイテンシーとRecallのトレードオフを定める。基本的には数値が大きいほど、レイテンシーとRecallが高くなる。
- 各ノードが持てる最大リンク数:
m - 検索捜査時に訪れる候補ノードのキューのサイズ:
ef_search - ノード追加時に訪れる候補ノードのキューのサイズ:
ef_construction
- インフラ特性
- メモリを多く消費する
- メモリ使用量(opensearchの場合)
1.1 * (4 * {ベクトル次元} + 8 * {最大リンク数}) * {ベクトル数}次元 = 384, 最大リンク数 = 16, ベクトル数 = 1000万のとき≒ 37GB
- → ベクトル量子化などして消費メモリを抑える等工夫したほうが良い
- メモリ使用量(opensearchの場合)
- メモリを多く消費する
参考/引用¶
- pgvectorを使ってChatGPTとPostgreSQLを連携してみよう!(PostgreSQL Conference Japan 2023 発表資料)
- NTT データグループ の人の資料(HNSWの概要掴むのに良い)
- 日本語訳: ベクトルデータベース(パート3): すべてのインデックスが同じとは限らない
- Vector databases (3): Not all indexes are created equal の和訳
- Hierarchical Navigable Small Worlds (HNSW)
- HNSW解説サイト(英語)
- AWSブログ:OpenSearch における 10 億規模のユースケースに適した k-NN アルゴリズムの選定
- k-NNアルゴリズムに関するAWSブログ
- Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
- HNSWの論文
- onensearch Approximate k-NN search
- opensearchにおけるhnsw利用
- pgvector
- pgvectorにおけるhnsw利用