Diffusion Model について¶
画像生成AI¶
22年12月に公開された日本経済新聞の「AIが描く絵 見分けられる?」のように人間が作成したものかどうかの区別が難しくなるほど近年の画像生成AIの進化はめざましいものがある。
サービスとして公開されているものは以下のものが代表される
Diffusion Model(拡散モデル)¶
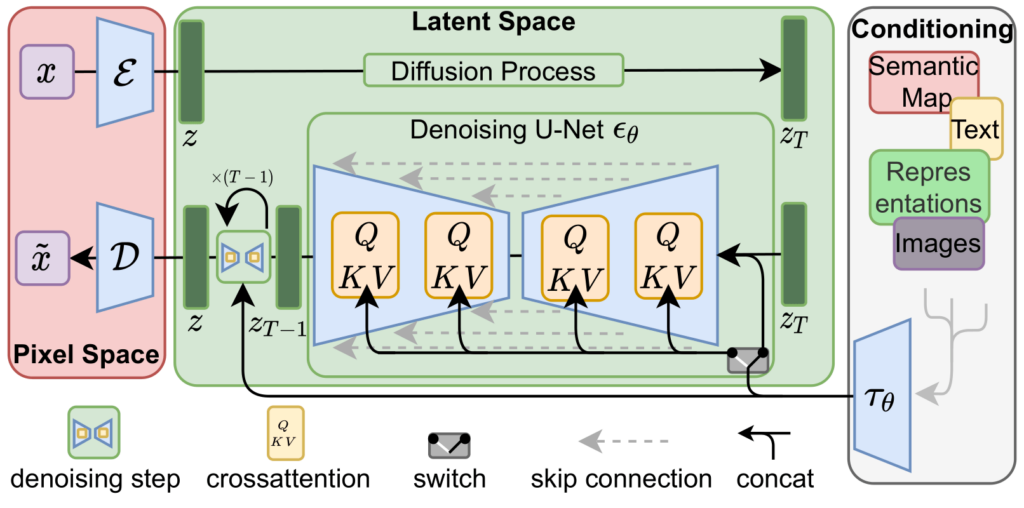
High-Resolution Image Synthesis with Latent Diffusion Modelsで提唱されている画像生成手法。 主に下記のような特徴を有する。
- forward process(拡散過程)とreverse process(逆拡散過程)を用いて画像とノイズ間の変換を行う
- forward process
- 画像にノイズを加えながら、最終的にノイズ画像を生成する確率過程
- reverse process
- forward processの逆をたどることで画像を生成する確率過程
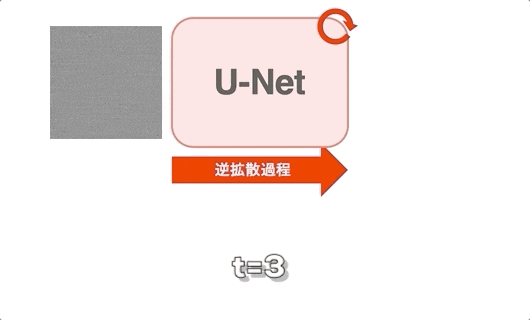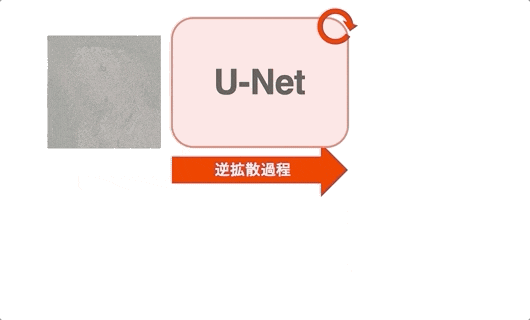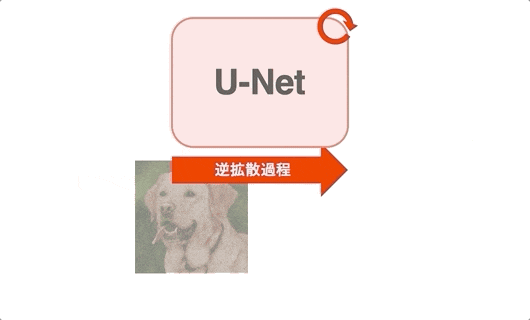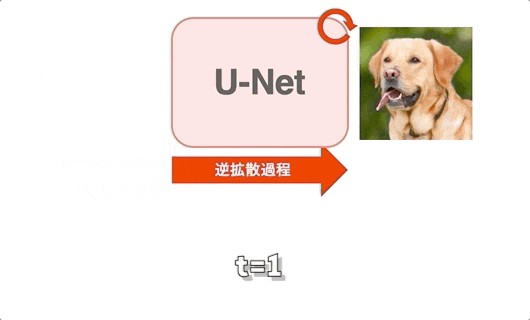
- U-Netを用いる
- forward process
- 画像生成する場合
- 乱数生成したノイズ画像に対してreverse processを実行して反復的にノイズを取り除くことで画像を生成する
- reverse processごとに潜在空間でベクトル化したConditioningのtextや画像をconcatすることで、生成内容に指向性を持たせる
- 最終的に逆拡散後の潜在空間ノイズにVAE(Variational Autoencoder) Decorderをかけて、画像に戻す。
- 乱数生成したノイズ画像に対してreverse processを実行して反復的にノイズを取り除くことで画像を生成する
- 参考
Diffusion Model¶
reverse process(逆拡散過程)のイメージ¶
U-Netの出力は潜在空間ノイズなので厳密には画像ではないことに注意すること。
画像化するときはVAEを用いて潜在空間ノイズから変換する。
forward process と reverse process の関係¶
